In this blog post, we will use the LogisticRegression module from scikit-learn to confidently determine the species of a penguin in the smallest number of measurements necessary. Our set of data is given in the table below.
We need to find the combination of features with which we can determine the species of a penguin the fastest. We can accomplish this by running an exhaustive search of all the features contained in this data set. At each iteration, we use the LogisticRegression module to test the score on the current set of features.
from itertools import combinationsfrom sklearn.linear_model import LogisticRegression# these are not actually all the columns: you'll # need to add any of the other ones you want to search forall_qual_cols = ["Clutch Completion", "Sex", 'Island']all_quant_cols = ['Culmen Length (mm)', 'Culmen Depth (mm)', 'Flipper Length (mm)', 'Body Mass (g)']best_score =0best_col =0for qual in all_qual_cols: qual_cols = [col for col in X_train.columns if qual in col ]for pair in combinations(all_quant_cols, 2): cols =list(pair) + qual_cols LR = LogisticRegression() LR.fit(X_train[cols], y_train)if best_score < LR.score(X_train[cols], y_train): best_col = cols best_score = LR.score(X_train[cols], y_train)print(best_col)
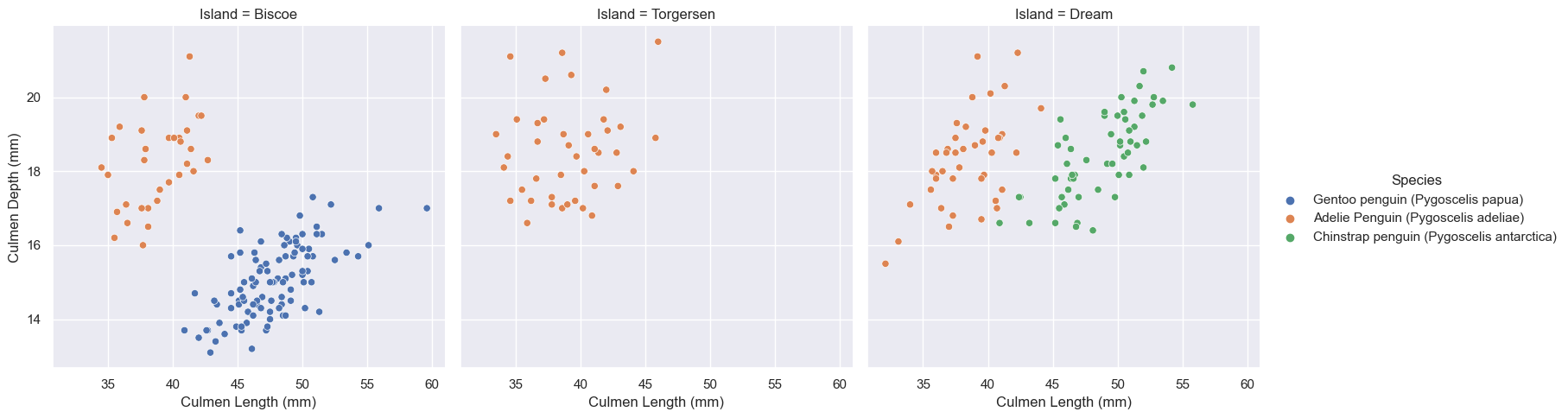
These tables give the range of culmen length and depth of the penguins on each island. For example, on Biscoe island, the culmen length range is 34.5 mm - 59.6 mm. This means that this island must have Adelie penguins on it because Adelie penguins have the shortest culmens. The 59.6 mm maximum suggests that the other species may be Gentoo or Chinstrap. The tight length range 33.5 mm - 46.0 mm suggests that there are only Adelie penguins on Torgensen island. By making quantitative comparisons like this, we can linearly separate our data.
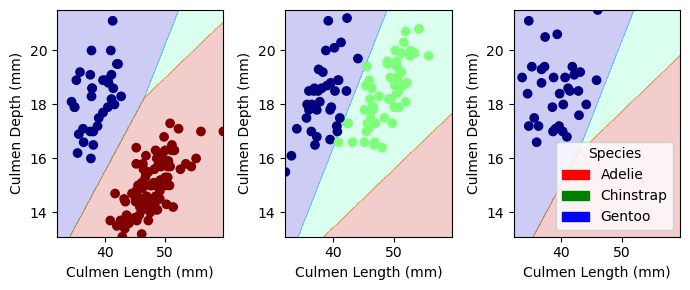
from matplotlib.patches import Patchimport matplotlib.pyplot as pltimport numpy as npdef plot_regions(model, X, y): x0 = X[X.columns[0]] x1 = X[X.columns[1]] qual_features = X.columns[2:] fig, axarr = plt.subplots(1, len(qual_features), figsize = (7, 3))# create a grid grid_x = np.linspace(x0.min(),x0.max(),501) grid_y = np.linspace(x1.min(),x1.max(),501) xx, yy = np.meshgrid(grid_x, grid_y) XX = xx.ravel() YY = yy.ravel()for i inrange(len(qual_features)): XY = pd.DataFrame({ X.columns[0] : XX, X.columns[1] : YY })for j in qual_features: XY[j] =0 XY[qual_features[i]] =1 p = model.predict(XY) p = p.reshape(xx.shape)# use contour plot to visualize the predictions axarr[i].contourf(xx, yy, p, cmap ="jet", alpha =0.2, vmin =0, vmax =2) ix = X[qual_features[i]] ==1# plot the data axarr[i].scatter(x0[ix], x1[ix], c = y[ix], cmap ="jet", vmin =0, vmax =2) axarr[i].set(xlabel = X.columns[0], ylabel = X.columns[1]) patches = []for color, spec inzip(["red", "green", "blue"], ["Adelie", "Chinstrap", "Gentoo"]): patches.append(Patch(color = color, label = spec)) plt.legend(title ="Species", handles = patches, loc ="best") plt.tight_layout()
plot_regions(LR, X_train[best_col], y_train)
These 3 graphs correspond to the 3 islands: Biscoe, Dream and Torgensen.
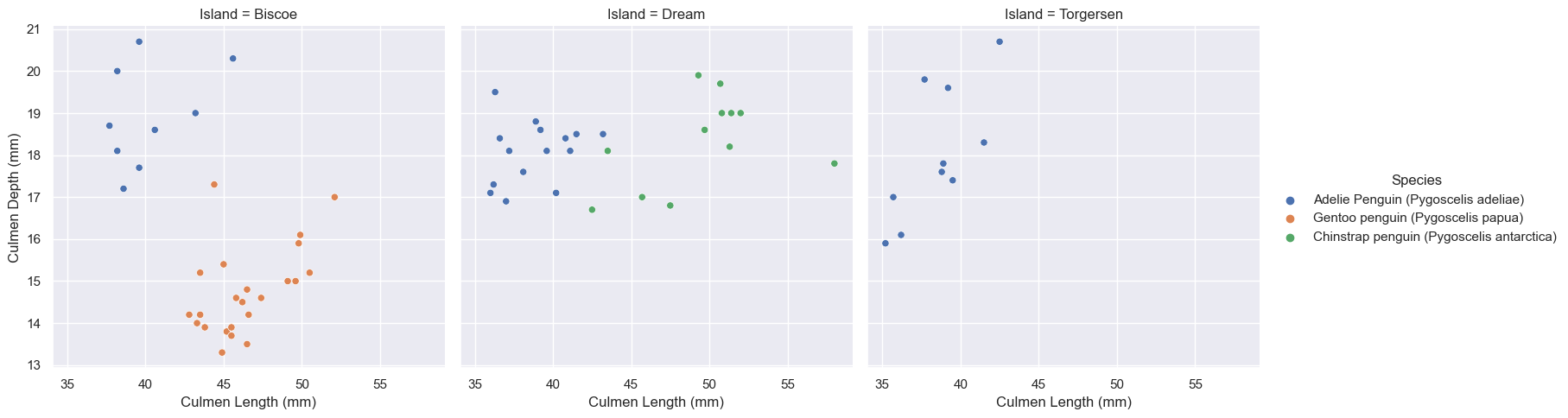
Now that we have established that “Culmen Length”, “Culmen Depth” and “Island” make the best feature combination, we will test this out on new data.