Optimization algorithms based on the gradients of functions.
Author
Trong Le
Published
February 26, 2023
The optimization for logistic loss can be implemented by using my source code solutions.py, which can be found HERE. In this code, loss optimization is implemented in three ways with the gradient descent: plain gradient descent, batch gradient descent, and gradient descent with momentum.
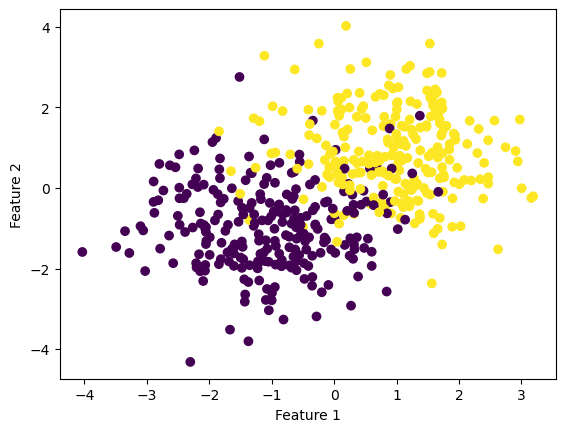
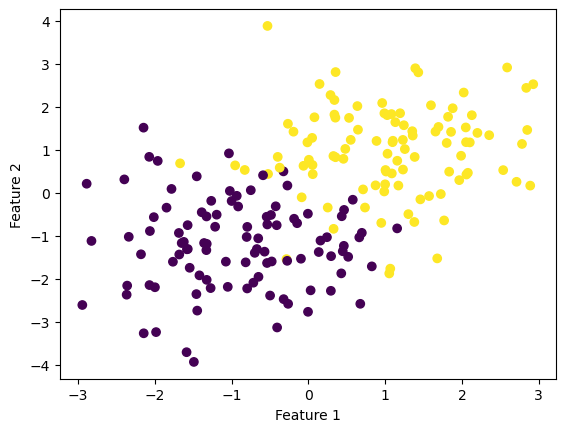
Below is our data, which is not linearly separable.
from solutions import LogisticRegressionfrom sklearn.datasets import make_blobsfrom matplotlib import pyplot as pltimport numpy as npnp.seterr(all='ignore') # make the datap_features =3X, y = make_blobs(n_samples =500, n_features = p_features -1, centers = [(-1, -1), (1, 1)])fig = plt.scatter(X[:,0], X[:,1], c = y)xlab = plt.xlabel("Feature 1")ylab = plt.ylabel("Feature 2")
def sigmoid(z):# the sigmoid functionreturn1/ (1+ np.exp(-z))
n, p = X.shape# weight tilda and X tilda that has one extra termw_tilda = np.random.rand(p+1)X_tilda = np.append(X, np.ones((X.shape[0], 1)), 1)y_hat = np.dot(X_tilda, w_tilda) #inner product between X and wdeltaL =1/n*(sigmoid(y_hat) - y)@X_tildadeltaL
array([-0.22233893, -0.1366533 , 0.09319262])
1. Gradient Descent
The gradient descent algorithm is implemented when the LogisticRegression.fit(X, y) is called. \(\textbf{X}\) is the feature matrix, and \(\textbf{y}\) is the target vector, as we know from the perceptron blog post. We need to find a weight vector that can minimize the logistic loss on \(\textbf{X}\) and \(\textbf{y}\) by updating the weight in a loop. At every loop:
compute the gradient descent of the logistic loss, which is given by \[\nabla L(\textbf{w}) = \frac{1}{n} \sum^n_{i=1} (\sigma (\langle \textbf{w}, \textbf{x}_i \rangle), y_i) \textbf{w}_i, \] where \(\sigma(z)\) denotes the sigmoid function.
update the weight until the logistic loss does not change \[\textbf{w}^{(t+1)} = \textbf{w}^{(t)} - \alpha \nabla L(\textbf{w}^{(t)})\]
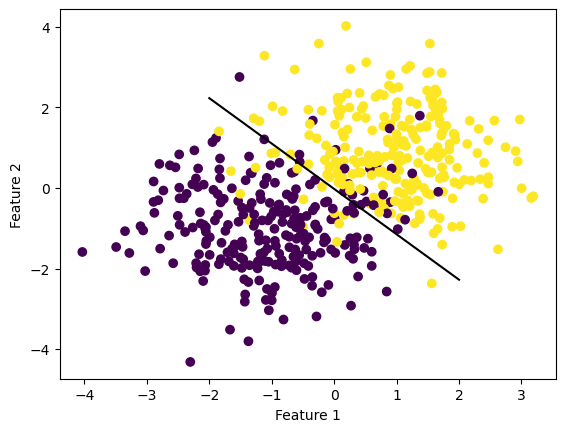
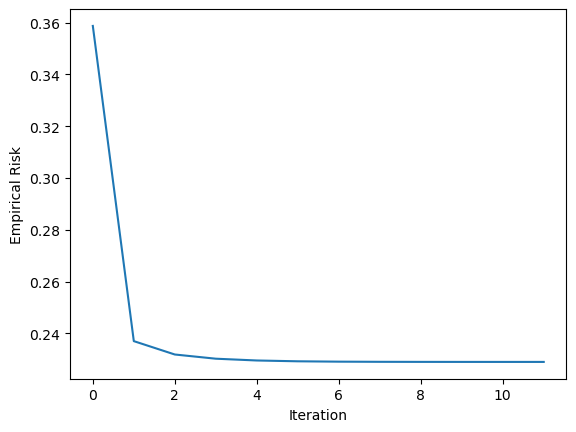
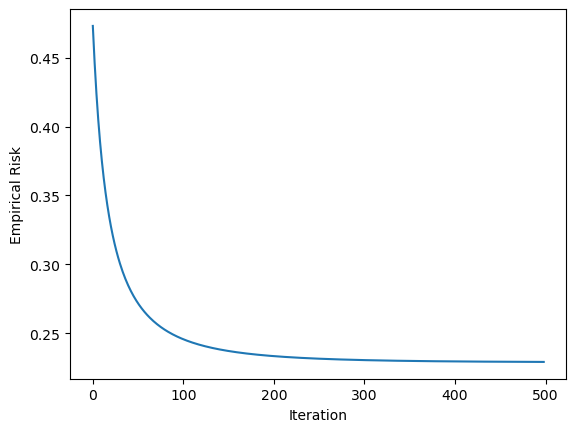
# fit the modelLR = LogisticRegression()LR.fit(X, y, alpha =10, max_epochs =1000)# inspect the fitted value of wLR.w def draw_line(w, x_min, x_max): x = np.linspace(x_min, x_max, 101) y =-(w[0]*x + w[2])/w[1] plt.plot(x, y, color ="black")figy, axy = plt.subplots()axy.scatter(X[:,0], X[:,1], c = y)draw_line(LR.w, -2, 2)axy.set_xlabel("Feature 1")axy.set_ylabel("Feature 2")figx, axv = plt.subplots()axv.plot(LR.loss_history)axv.set_xlabel("Iteration")axv.set_ylabel("Empirical Risk")plt.show()
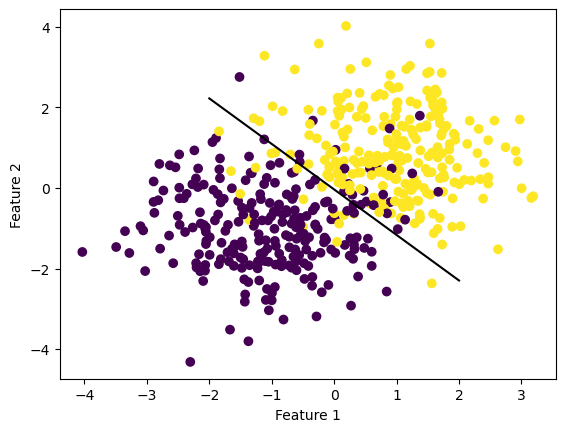
In this case, the learning rate was set very high to 10, which caused the algorithm to converge too soon and leave the logistic loss at 0.24. As we change the learning rate to 0.1, we can see that the loss fell to 0.24.
LR = LogisticRegression()LR.fit(X, y, alpha=0.1, max_epochs=1000)figy, axy = plt.subplots()axy.scatter(X[:,0], X[:,1], c = y)draw_line(LR.w, -2, 2)axy.set_xlabel("Feature 1")axy.set_ylabel("Feature 2")figx, axv = plt.subplots()axv.plot(LR.loss_history)axv.set_xlabel("Iteration")axv.set_ylabel("Empirical Risk")plt.show()
2. Stochastic Gradient Descent
The stochastic gradient descent algorithm is implemented by the LogisticRegression.fit_stochastic(X, y) method. In this algorithm, instead of computing the complete gradient as in part 1, we compute a stochastic gradient by picking a random subset \(S \subseteq [n] = \{1, ..., n\}\) and computing
The size of \(S\) is the batch size, which we can refer to as \(k\). The batch gradient descent is performed as follows: 1. Shuffle the points randomly. 2. Pick the first \(k\) random points, compute the stochastic gradient, and then perform an update. 3. Pick the next \(k\) random points and repeat.. 4. When we have gone through all \(n\) points, reshuffle them all randomly and proceed again.
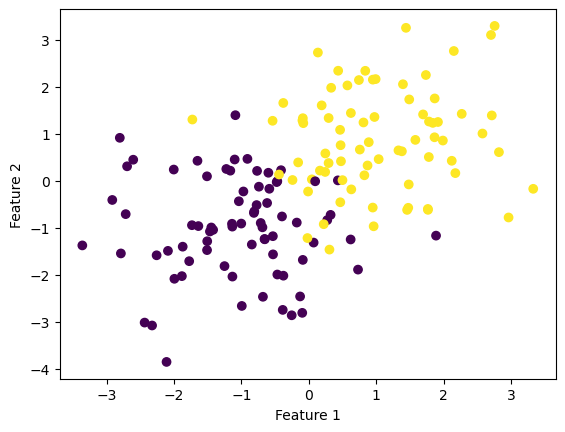
np.seterr(all='ignore') # make the datap_features =3X, y = make_blobs(n_samples =200, n_features = p_features -1, centers = [(-1, -1), (1, 1)])fig = plt.scatter(X[:,0], X[:,1], c = y)xlab = plt.xlabel("Feature 1")ylab = plt.ylabel("Feature 2")
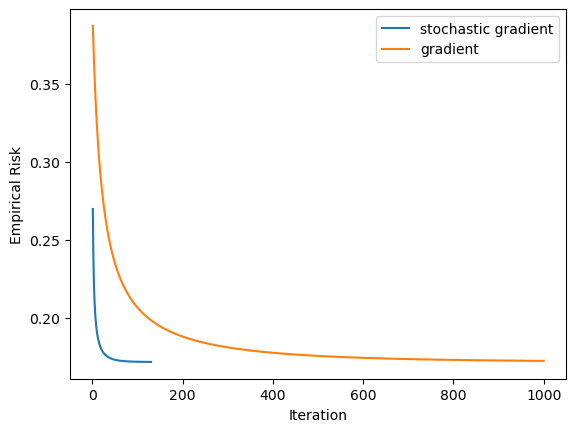
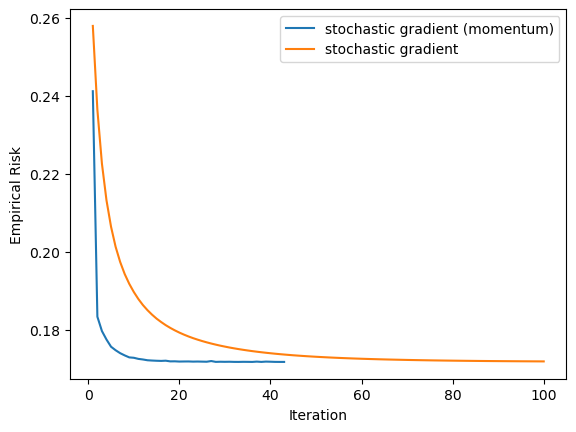
In this experiment, we can see how the stochastic gradient descent algorithm can outperform the original gradient descent method.
The idea here is that if the previous weight update was good, we may want to continue moving along this direction. To test how the momentum can help with accelerating convergence, we choose a small sample size of 150, distributed among 10 features.
np.seterr(all='ignore') # make the datap_features =11X, y = make_blobs(n_samples =150, n_features = p_features -1, centers = [(-1, -1), (1, 1)])fig = plt.scatter(X[:,0], X[:,1], c = y)xlab = plt.xlabel("Feature 1")ylab = plt.ylabel("Feature 2")