The code to implement the Adam optimizer for logistic regression can be found HERE.
In this blog post, I will use Adam optimization to conduct some experiments and confirm that Adam optimization is more efficient than stochastic gradient descent. From Kingma and Ba’s paper about the Adam algorithm, there are a few factors that contribute to its efficient convergence: - Adaptive learning rates for each parameter: Adam adapts the learning rate for each parameter based on the historical first and second moments of the gradients, which helps the algorithm to converge quickly and effectively. - Momentum-based updates: Adam includes a momentum term that helps to smooth out the gradients and speed up convergence. - Bias correction: Adam uses a bias correction step to correct for the fact that the first and second moments estimates are biased towards zero in the initial stages of training.
Spoiler alert: all the experiments in this blog post go to prove that stochastic gradient descent converges slower than Adam! Adam’s efficiency is a direct result of its complexity: implementing the Adam algorithm is more complex than implementing standard stochastic gradient descent, as it involves additional computations for the adaptive learning rates and momentum-based updates.
A. Stochastic Gradient Descent vs. Adam Optimization
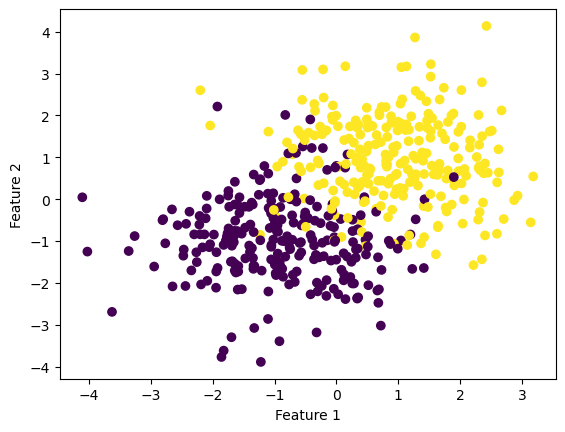
We will use the data given below to compare between stochastic logistic regression and Adam optimization.
from solutions import LogisticRegressionfrom sklearn.datasets import make_blobsfrom matplotlib import pyplot as pltimport numpy as npnp.seterr(all='ignore') # make the datap_features =3X, y = make_blobs(n_samples =500, n_features = p_features -1, centers = [(-1, -1), (1, 1)])fig = plt.scatter(X[:,0], X[:,1], c = y)xlab = plt.xlabel("Feature 1")ylab = plt.ylabel("Feature 2")
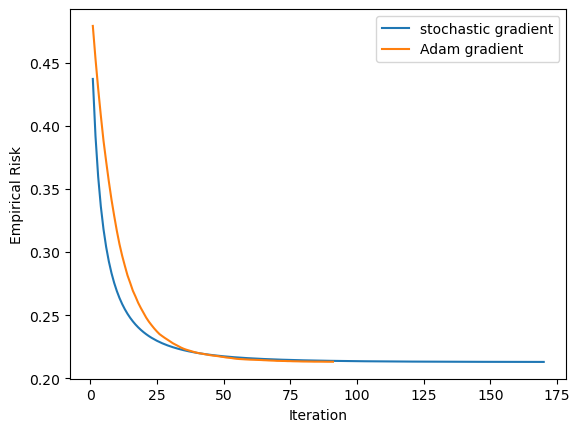
The learning rate for the stochastic gradient method is 10 times bigger than that for the Adam method, but the Adam method converges in half the time steps!
B. Digits Experiment
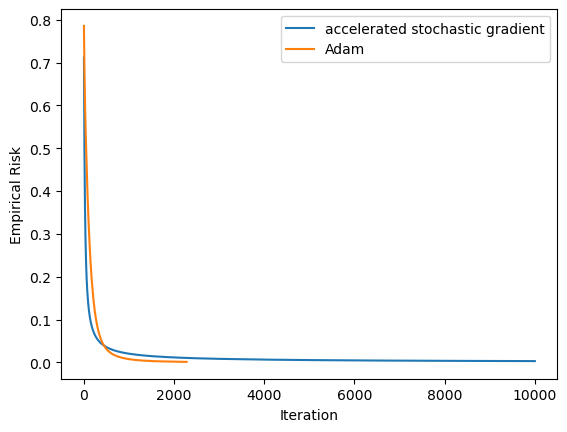
We will use the digits dataset from sklearn. I will filter the digits data set so that it only contains data with two class labels, namely 0s and 1s.
from sklearn.datasets import load_digitsfrom sklearn.model_selection import train_test_split# Load the datasetdigits = load_digits()# Filter the data to only contain 4s and 8sX = digits.data[(digits.target ==0) | (digits.target ==1)]y = digits.target[(digits.target ==0) | (digits.target ==1)]# Split the data into training and testing setsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
So it seems that the Adam optimization is much faster than the stochastic gradient with momentum method! And now we will compare their efficiencies on unseen data.
print('The score of the Adam machine is '+str(LR_Adam.score(X_test/255, y_test)) +'.')print('The score of the accelerated stochastic gradient method is '+str(LR_momentum.score(X_test/255, y_test)) +'.')print('The loss of the Adam machine is '+str(LR_Adam.loss(X_test/255, y_test)) +'.')print('The loss of the accelerated stochastic gradient method is '+str(LR_momentum.loss(X_test/255, y_test)) +'.')
The score of the Adam machine is 1.0.
The score of the accelerated stochastic gradient method is 1.0.
The loss of the Adam machine is 0.49792824663572666.
The loss of the accelerated stochastic gradient method is 0.49792824663572666.
These numbers look the same, but the Adam machine achieved these numbers in a much faster fashion.
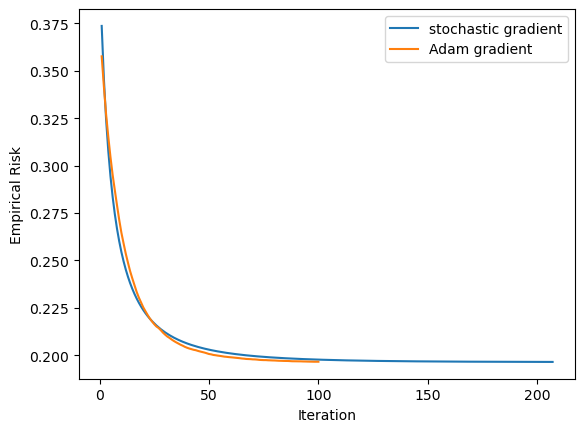
One More Experiment
I will do one more experiment on a dataset that looks like the one in section A, except that there are 80 features.
# make the datap_features =81X, y = make_blobs(n_samples =500, n_features = p_features -1, centers = [(-1, -1), (1, 1)])